AI Trainer
Purpose
The AI Trainer Processor trains one or more AI models using message data collected from a Workflow. It reads attribute values from incoming messages, assembles them into a training dataset, trains a machine learning model using the Weka library, and stores the trained model in the cluster's AI Storage.
The trained model is then used by an AI Classifier Processor to classify new messages.
Use this Processor to:
- Train a classification model from historical or sample message data
- Collect training data over time (time/message-based mode) or in batches (stream-based mode)
- Store a trained model in AI Storage that can be deployed for real-time classification
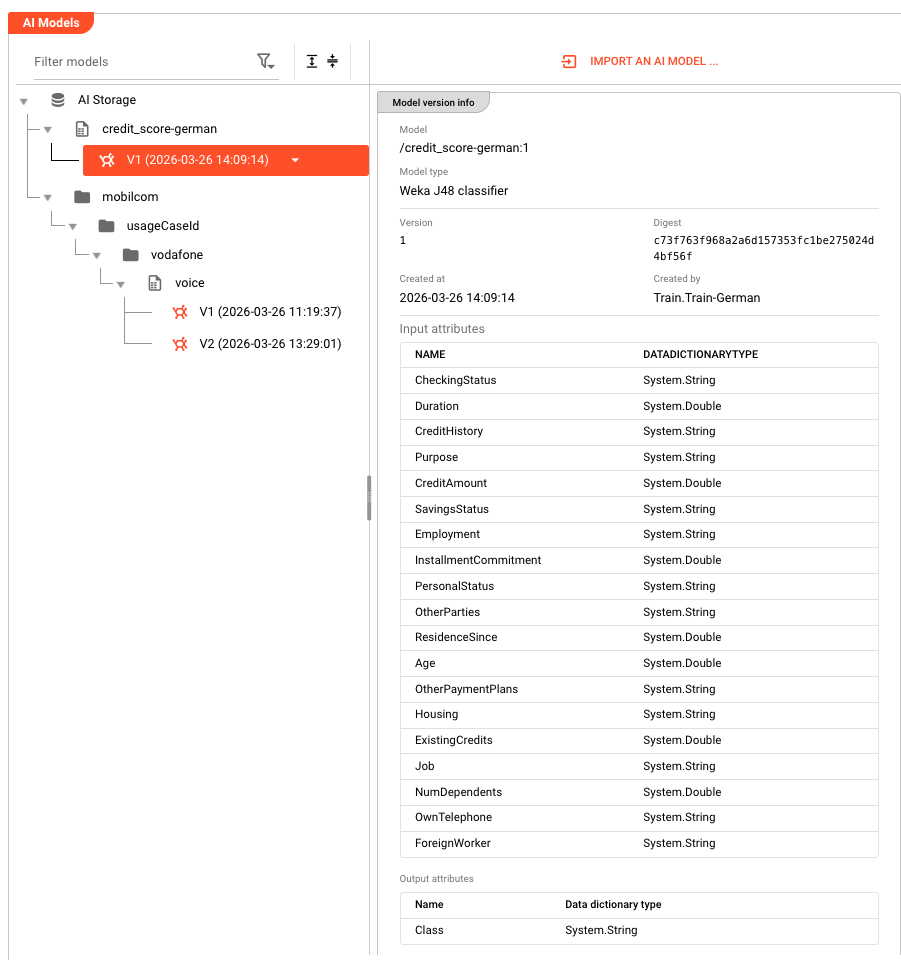
Each training run creates a new version of the model in AI Storage, identified by a running number. Use :latest to reference the most recent version, or :<version-number> to reference a specific version.
Prerequisites
This processor requires:
- An AI Model Resource that defines the model's input/output attributes, model type (e.g., J48 Decision Tree, Multilayer Perceptron), and hyperparameters
- A path in AI Storage where the trained model will be stored
- Incoming messages with attribute values that can be mapped to the model's input schema
How Training Works
The Trainer accumulates message data as training samples and then runs a Weka model training algorithm. The steps are:
- Collect — read attribute values from each incoming message using the configured input attribute mappings
- Aggregate — store collected samples until the training trigger conditions are met
- Train — run the selected Weka training algorithm on the collected dataset
- Store — save the trained model to the configured path in AI Storage
Each training run creates a new version of the model. The path combined with the version number uniquely identifies each model version in AI Storage.
Configuration
Name & Description
Name: Name of the Asset. Spaces are not allowed in the name.
Description: Enter a description.
Input Ports

This Processor can only have one Input Port from which it receives data to process.
A port can have a name and description. A Name is mandatory.
You cannot delete the only Input Port.
Output Ports
This Processor can only have one Output Port to send messages on within the Workflow.

A port can have a name and description. A Port Name is mandatory.
You cannot delete the only Output Port.
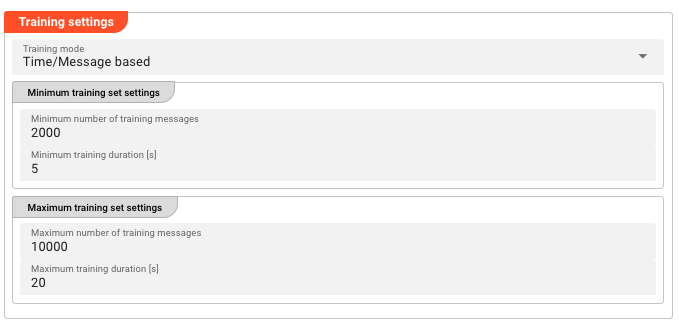
Training Settings
Training mode
Controls how and when training data is collected and when training is triggered.
| Option | Description |
|---|---|
| Stream based | All messages from the same stream are collected as one training batch. Training starts when the stream ends (onCommit). Use this when you have a complete labeled dataset in one stream. |
| Time / Message based | Messages are collected continuously over time. Training begins when at least one of the minimum conditions (message count or duration) is satisfied, and ends when at least one of the maximum conditions (message count or duration) is reached. Use this for continuous data collection with periodic retraining. |
Training set limits (Time / Message based only)
Configure the boundaries for when training starts and stops:
Minimum training set:
| Field | Description |
|---|---|
| Minimum number of training messages | The minimum number of messages required before training can be performed. If fewer messages are received than this threshold, training will not run. |
| Minimum training duration [s] | The minimum duration (in seconds) that training data must be streamed before training can be performed. |
Maximum training set:
| Field | Description |
|---|---|
| Maximum number of training messages | The maximum number of messages to collect before training ends. |
| Maximum training duration [s] | The maximum duration (in seconds) before training ends, regardless of message count. |
Training begins when at least one minimum condition is satisfied, and ends when at least one maximum condition is reached. Stream-based mode does not use these parameters — all incoming messages are used for training regardless of count or duration.
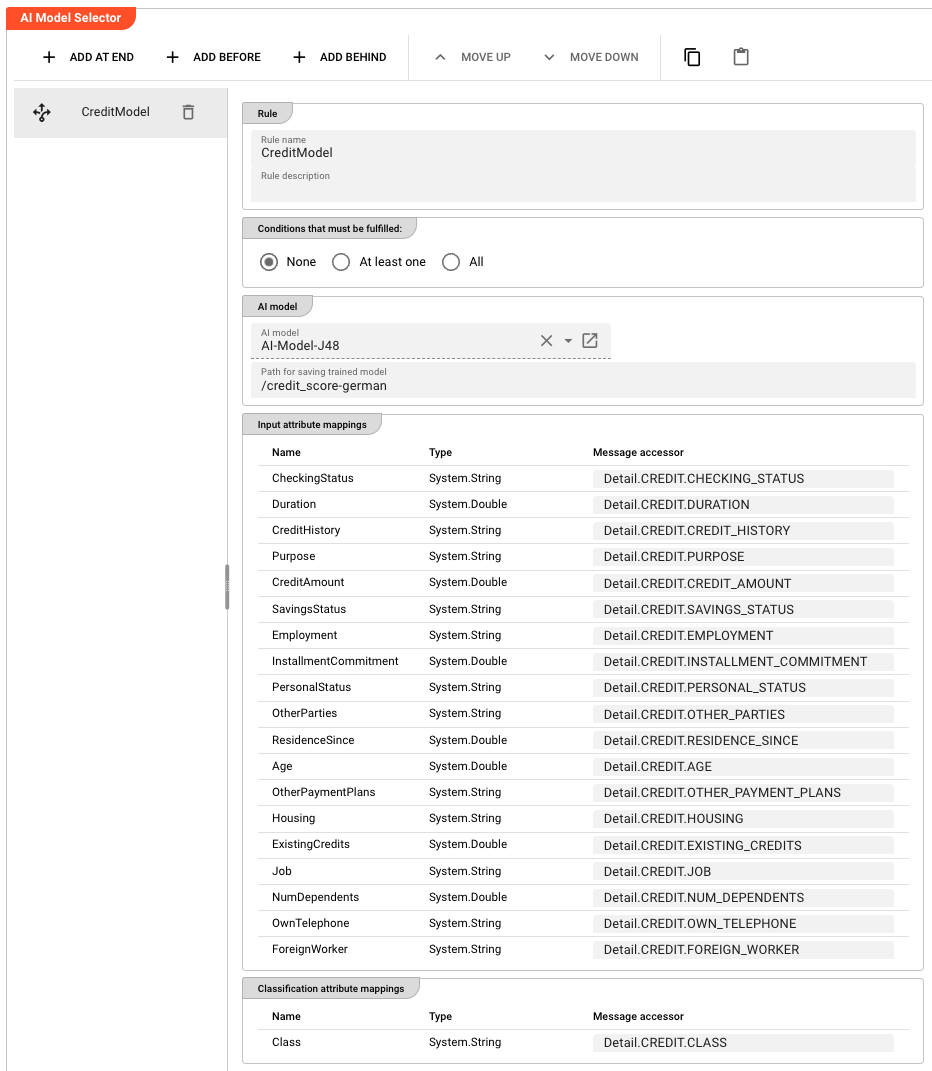
Models to train
The models table lists all AI Model Resources to train and where to store each trained model in AI Storage.
Click + ADD MODEL to add a new model configuration. Each row has:
| Column | Description |
|---|---|
| Model name | A human-readable name for this trained model (e.g., VoiceClassifier-v2) |
| Path in AI Storage | The path in AI Storage where the trained model will be stored (e.g., models/my-classifier). Supports macros for per-environment values. |
| AI Model | Reference to an existing AI Model Resource in the Project — defines the input/output schema, model type, and hyperparameters |
| Model type | The Weka algorithm to use (read from the selected AI Model Resource, e.g., J48 Decision Tree, Multilayer Perceptron) |
The AI Model Resource defines:
- Input attributes — the attribute names and types that the model expects as input
- Output attribute — the attribute that the model will predict (the class label)
- Model type — the Weka algorithm (Decision Tree / Neural Network)
- Hyperparameters — algorithm-specific settings (e.g., for J48: unpruned tree, minimum number of objects per leaf; for MLP: learning rate, momentum, hidden layers)
Input attribute mappings
For each selected AI Model, defines how incoming message data maps to the model's input attributes.
Each row maps a Data Dictionary attribute (from the AI Model Resource's input schema) to a message accessor:
| Column | Description |
|---|---|
| Name | The attribute name from the AI Model Resource's input schema (read-only) |
| Type | The attribute's data type from the Data Dictionary (read-only) |
| Message accessor | A message accessor expression that reads the value from the current message |
These are the features that will be fed to the Weka model during training.
Behavior
Stream Based Mode
- Each message in the stream is added to the training batch as a training sample
- The input attribute mappings are used to extract feature values from each message
- When the stream ends (onCommit), the collected batch is used to train the model
- The trained model is stored in AI Storage at the configured path
- If the stream contains fewer messages than
Minimum number of training messages, training is skipped
Time / Message Based Mode
- Messages are collected continuously over time
- Each message adds to the training batch
- Training starts when at least one minimum condition is satisfied (message count OR time elapsed)
- Training ends when at least one maximum condition is reached (message count OR time elapsed)
- If neither maximum is set, training never triggers automatically (manual reset required)
- After training, the batch is cleared and collection begins again for the next training cycle
Inheritance
All settings support inheritance — a child Asset can override individual models or fields while inheriting the rest from its parent.
Example
A Workflow receives usage records and needs to train a classification model to categorize records by type.
The JavaScript Processor extracts and formats the relevant attributes from each record before passing them to the Trainer.
AI Trainer configuration:
| Setting | Value |
|---|---|
| Training mode | Time / Message based |
| Minimum number of training messages | 1000 |
| Maximum number of training messages | 10000 |
Models to train:
| Model name | Path to trained model file | AI Model | Model type |
|---|---|---|---|
UsageClassifier-v2 | models/usage-classifier-v2 | UsageClassifier | J48 Decision Tree |
Input attribute mappings:
| Attribute | Message accessor |
|---|---|
call_type_ind | Detail.D2_05.CALL_TYPE_IND |
call_destination_ind | Detail.D2_05.CALL_DESTINATION_IND |
rate_scenario_cd | Detail.D2_05.RATE_SCENARIO_CD |
| ... | Detail.D2_05.* |
What happens at runtime:
- Messages arrive with raw attributes from the source
- The JavaScript Processor extracts and formats the relevant fields
- The AI Trainer collects the formatted messages into a training batch
- After 1000+ messages have been collected, the Trainer assembles the feature data into a Weka dataset
- The J48 Decision Tree algorithm trains on the dataset
- The trained model is stored in AI Storage at
models/usage-classifier-v2 - The model is now available for the AI Classifier to load and use for classification
See Also
- AI Classifier — for applying a trained model to classify new messages
- AI Model Resource — for defining the model's input/output schema, algorithm type, and hyperparameters
- AI Service — for defining the interface to an AI model
- Operations → AI Storage — for managing trained models in AI Storage
- Using Artificial Intelligence in Workflows — conceptual overview of supervised learning in layline.io
Please note, that the creation of the online documentation is Work-In-Progress. It is constantly being updated. should you have questions or suggestions, please don't hesitate to contact us at support@layline.io .